
Operator 通常将 Percona XtraDB 集群备份存储在 Kubernetes 集群外部的Amazon S3 或 S3 兼容存储上: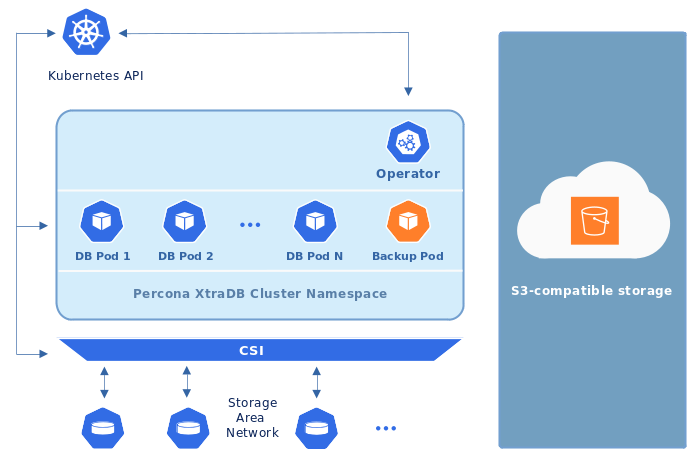
但是也可以在 Kubernetes 集群内的Persistent Volumes上存储备份: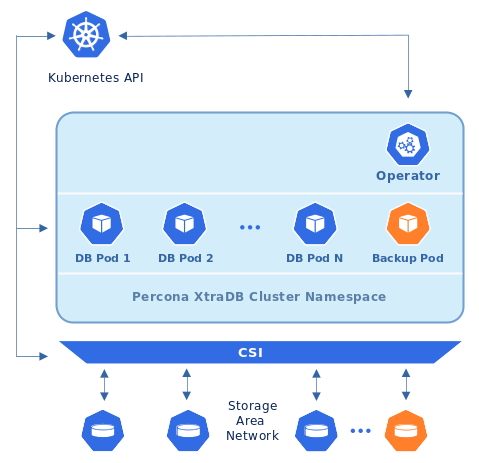
Operator 允许以两种方式进行备份。 计划备份在 deploy/cr.yaml 文件中配置为在适当的时间自动执行。 可以随时手动进行按需备份。
模板yaml: https://github.com/percona/percona-xtradb-cluster-operator/blob/main/deploy/cr.yaml
计划备份
由于备份单独存储在 Amazon S3 上,因此 Kubernetes 集群上应该存在一个 AWS_ACCESS_KEY_ID密钥AWS_SECRET_ACCESS_KEY。应创建具有这些 base64 编码密钥的机密文件:例如deploy/backup-s3.yaml具有以下内容的文件:
1 | apiVersion: v1 |
Note: 以下命令可用于从纯文本中获取 base64 编码的字符串:$ echo -n ‘plain-text-string’ | base64
该name值是Kubernetes Secret 名称,它将被进一步使用,AWS_ACCESS_KEY_ID并且 AWS_SECRET_ACCESS_KEY是访问 S3 存储的密钥(显然它们应该包含适当的值以使这种访问成为可能)。要使机密文件生效,应使用适当的命令来创建机密对象,例如 (对于 Kubernetes)。kubectl apply -f deploy/backup-s3.yaml
Note: 如果之前的备份尝试失败(由于临时网络问题等),备份作业会首先尝试删除不成功的备份剩余部分,然后重试。因此,如果没有对存储桶中对象的 DELETE 权限,将不会进行备份重试。此外,设置Google Cloud Storage 保留期 可能会导致类似问题。
备份计划在deploy/cr.yaml 文件的backup部分中 定义。本节包含以下小节:
- storages小节包含访问与 S3 兼容的云以存储备份所需的数据。
- schedulesubsection 允许实际计划备份(计划以 crontab 格式指定)。
以下是使用 Amazon S3 存储进行备份的deploy/cr.yaml示例:
1 | ... |
如果您使用一些与 S3 兼容的存储而不是原始 Amazon S3,则在s3小节中需要endpointUrl ,它指向用于备份的实际云,并且特定于云提供商。例如,使用Google Cloud涉及到以下endpointUrl:
1 | endpointUrl: https://storage.googleapis.com |
这三个小节中的选项在 自定义资源选项中进一步解释。
应该单独提及的一个选项是, 用于备份credentialsSecret的Kubernetes secrets 。此键的值应与用于创建secret对象的名称相同(my-cluster-name-backup-s3在最后一个示例中)。
计划以 crontab 格式指定,如 自定义资源选项中所述.
按需备份(手动备份)
要进行按需备份,用户应首先在配置文件的backup.storages小节中配置备份存储,其deploy/cr.yaml方式与为计划备份所做的方式相同。当 deploy/cr.yaml文件包含正确配置的存储并通过kubectl命令应用时,请使用具有以下内容的特殊备份配置 YAML 文件:
- backup name in the metadata.name key,
- Percona XtraDB Cluster name in the spec.pxcCluster key,
- storage namefrom deploy/cr.yaml in the spec.storageName key,
- S3 backup finalizer set by the metadata.finalizers.delete-s3-backup key (当有手动或计划删除相应的备份对象时,它会触发从 S3 存储桶中实际删除备份文件).
Note: 示例文件: https://github.com/percona/percona-xtradb-cluster-operator/blob/main/deploy/backup/backup.yaml
当使用kubectl apply -f deploy/cr.yaml命令配置和应用备份目标时,会执行实际的备份命令:
1 | kubectl apply -f deploy/backup/backup.yaml |
存储binlog 以进行时间点恢复
Point-in-time恢复功能允许用户将集群回滚到特定的事务、时间(甚至在某些情况下跳过事务)。从技术上讲,此功能涉及将binary log更新连续保存到备份存储中。时间点恢复默认关闭,Operator 仅支持从 8.0.21-12.1 开始的 Percona XtraDB Cluster版本。
要使用它,需要在deploy/cr.yaml文件部分pitr下的backup 部分中设置一些键:
- enabled键应设置为true,
- storageNamekey 应该指向已经在storages部分中配置的存储的名称(目前,仅支持与 s3 兼容的存储),
- timeBetweenUploadskey 指定运行 binlog uploader 之间的秒数。
以下示例显示了该pitr部分的Yaml:
1 | backup: |
Note: 当您启用时间点恢复时,建议使用空的存储桶/目录来保存二进制日志(没有来自先前尝试或其他集群的二进制日志或文件)
Note: 在传输到备份存储之前清除 binlog 会破坏时间点恢复
在持久卷上存储备份
这是 deploy/cr.yaml 备份部分片段的示例,它为文件系统类型的存储配置私有卷:
1 | ... |
Note: 请注意,此示例中指定的 6Gi 存储大小可能不足以满足实际设置;考虑使用数十或数百 GB。deploy/cr.yaml此外,您可以稍后编辑此选项,更改将在应用更新后的文件使用kubectl生效 。
为备份启用压缩
可以为备份启用 LZ4 压缩
Note: 此功能仅适用于 Percona XtraDB Cluster 8.0,不适用于 Percona XtraDB Cluster 5.7。
要启用压缩,请使用 deploy/cr.yaml 配置文件中的pxc.configuration键,在其[sst]和 [xtrabackup] 部分下为 Percona XtraDB Cluster 节点提供两个额外的 my.cnf 选项,如下所示:
1 | pxc: |
启用后,压缩将被SST和backups同时启用。
从之前保存的备份中恢复集群
不仅可以在创建备份的 Kubernetes 集群上恢复备份,还可以在安装了 Operator 的任何基于 Kubernetes 的环境中恢复备份。
备份无法恢复到 emptyDir 和 hostPath 卷,但可以从此类存储(即从 emptyDir/hostPath 到 S3)进行备份,然后将其恢复到 Persistent Volume。
Note: 恢复到新的基于 Kubernetes 的环境时,请确保它有一个 Secrets 对象,该对象的用户密码与原始集群中的用户密码相同。有关Secret 的更多详细信息可以在系统用户中找到.
恢复以前保存的备份需要以下内容:
- 确保集群正在运行。
- 找出备份和集群的正确名称。可以使用以下命令列出可用的备份:
1 | kubectl get pxc-backup |
Note: 显然,只能在之前进行备份的同一集群上进行此检查
以下命令将列出当前基于 Kubernetes 的环境中现有的 Percona XtraDB 集群名称:
1 | kubectl get pxc |
不使用point-in-time恢复备份
当备份和集群的正确名称已知时,可以通过以下方式进行备份恢复。
deploy/backup/restore.yaml在文件中设置适当的键将
spec.pxcClusterkey设置为目标集群的名称以恢复备份,如果您要在同一个基于 Kubernetes 的集群上恢复备份 用于保存此备份,将
spec.backupName键设置为备份的名称如果您在基于 Kubernetes 的集群上恢复备份,而不是用于保存此备份的集群,请设置
spec.backupSource小节而不是spec.backupName字段以指向适当的 PVC 或 S3 兼容存储:如果备份存储在 PVC 卷上,则
backupSource应包含存储名称(应在主 CR 中配置)和 PVC 名称:... backupSource: destination: pvc/PVC_VOLUME_NAME storageName: pvc ...如果备份存储在与 S3 兼容的存储中,则
backupSource应包含与s3存储桶相同的目标键,并带有特殊的s3://前缀,后跟必要的S3配置键,与 `deploy/cr.yaml1 文件中的相同:... backupSource: destination: s3://S3-BUCKET-NAME/BACKUP-NAME s3: credentialsSecret: my-cluster-name-backup-s3 region: us-west-2 endpointUrl: https://URL-OF-THE-S3-COMPATIBLE-STORAGE ...
之后,可以按如下方式开始实际的恢复过程:
1 | kubectl apply -f deploy/backup/restore.yaml |
使用point-in-time恢复恢复备份
Note: 在现有集群上还原备份之前禁用现有集群上的时间点功能,无论备份是使用时间点恢复还是不使用时间点恢复。
如果启用了时间点恢复功能,您可以将额外的恢复参数放入 restore.yaml 文件的 pitr 部分,以获得最细粒度的恢复。
backupSourcekey 应该包含destination等于 s3 存储桶的 key,带有特殊s3://前缀,后跟必要的 S3 配置键,与deploy/cr.yamlfile:中相同s3://S3-BUCKET-NAME/BACKUP-NAME,
typekey 可以等于以下选项之一,
- date - 回滚到特定日期,
- transaction - 回滚到特定事务(自 Operator 1.8.0 起可用),
- latest - 恢复到最新的可能交易,
- skip - 跳过特定事务(自 Operator 1.7.0 起可用)。
date键与type=date选项一起使用 - 它包含日期时间格式的值,
gtid密钥(自 Operator 1.8.0 起可用)或gtidSet密钥(与 Operator 1.7.0 一起使用)与type=transaction选项一起使用 - 它包含确切的 GTID 或 GTIDSet(还原将不包括具有指定 GTID 的事务,但包含它之前的事务),
backup.storages 如果您有配置文件小节中提到的必要备份存储deploy/cr.yaml ,您可以 将文件中的backupSource.storageNamekey设置deploy/backup/restore.yaml为相应存储的名称,
如果 中没有必要的备份存储deploy/cr.yaml,请在小节中设置您的存储详细信息,backupSource.s3而不是使用以下 backupSource.storageName字段:
1 | ... |
生成的 restore.yaml 文件可能如下所示:
1 | apiVersion: pxc.percona.com/v1 |
实际的恢复过程可以如下开始:
1 | kubectl apply -f deploy/backup/restore.yaml |
删除不需要的备份
存储备份的最大数量由 backup.schedule.keep选项控制(仅计算成功的备份)。较旧的备份会自动删除,因此存储的备份量不会超过此数量。设置keep=0或删除此选项deploy/cr.yaml会禁用备份的自动删除。
手动删除以前保存的备份只需要备份名称。此名称可以从以下命令返回的可用备份列表中获取:
1 | kubectl get pxc-backup |
知道名称后,可以按如下方式删除备份:
1 | kubectl delete pxc-backup/<backup-name> |
将备份复制到本地计算机
制作以前保存的备份的本地副本只需要备份名称。此名称可以从以下命令返回的可用备份列表中获取:
1 | kubectl get pxc-backup |
知道名称后,可以将备份下载到本地机器,如下所示:
1 | ./deploy/backup/copy-backup.sh <backup-name> path/to/dir |
例如,这个下载的备份可以恢复到 Percona Server 的本地安装:
1 | service mysqld stop |